k8s node NotReady |
您所在的位置:网站首页 › k8s node not ready多久被驱逐 › k8s node NotReady |
k8s node NotReady
|
目录标题
NotReadyCase @1 may retry after sleepingCase @2 etcdserver: request timed outCase @ 3 container runtime status check may not have completed yet.Case @4 invalid capacity 0 on image filesystemCase @5 时间不一致Case @6 Error updating node status, will retryCase @7 dockerd 报错too many open filesCase@8 failed to update leaseCase@9 System OOM encountered, victim process: prometheus
NotReady
如果 Kubernetes 节点状态为 NotReady,这意味着节点无法执行其预定功能,并且不可用于调度新的工作负载。节点可能变为 NotReady 的原因有多种,包括: 网络问题:如果节点失去网络连接,它可能变为 NotReady。 ip -4 a资源耗尽:如果节点耗尽了 CPU 或内存等资源,它可能变为 NotReady。 free -h top节点故障:如果节点崩溃或经历硬件故障,它可能变为 NotReady。Kubernetes 组件故障:如果节点上的关键 Kubernetes 组件(如 kubelet 或 kube-proxy)发生故障,节点可能变为 NotReady。要排查 NotReady 节点,您可以: 使用 kubectl 命令检查节点状态:kubectl get nodes使用 kubectl 命令检查节点日志:kubectl describe ,并将输出重定向到文件:kubectl describe node > node.log在节点上检查 kubelet 日志:journalctl -xeu kubelet,并将输出重定向到文件:journalctl -xeu kubelet > kubelet.log;使用 systemctl 查看 kubelet 状态:systemctl status kubelet检查节点上的系统日志:/var/log/messages使用 kubectl 命令检查 Kubernetes 事件日志:kubectl get events检查 docker 状态:systemctl status docker && systemctl status containerd,使用管道查看更多信息:| more在节点上检查 docker 日志:journalctl -xeu docker,并将输出重定向到文件:journalctl -xeu docker > docker.log检查磁盘空间:df -h | head一旦确定了节点 NotReady 的根本原因,您可以采取适当的措施来解决问题。例如,如果节点由于资源耗尽而变为 NotReady,您可以为节点添加更多资源或调整运行在节点上的工作负载的资源限制。如果节点由于网络问题而变为 NotReady,您可以排查网络连接并修复任何问题。 /var/log/pods /var/log/containers crictl ps + crictl logs docker ps + docker logs (in case when Docker is used) kubelet logs: /var/log/syslog or journalctl
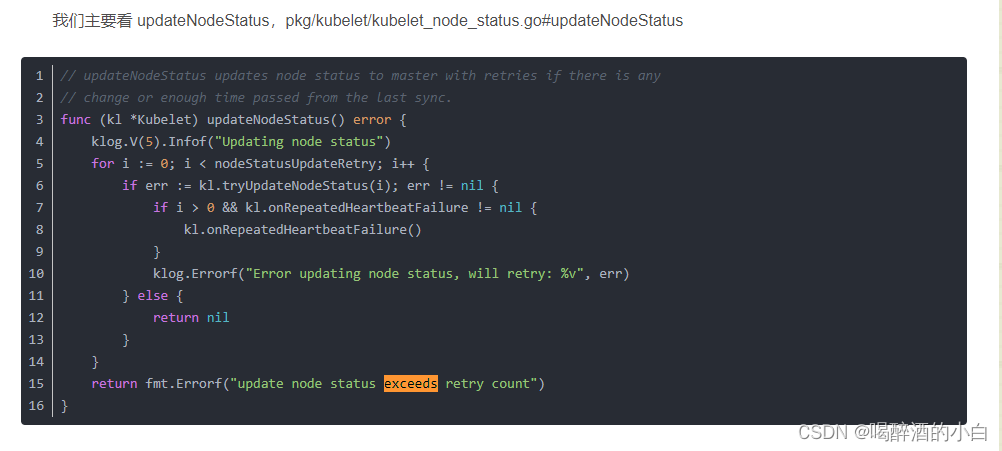
Issues 处理方案: systemctl restart kubelet Case @2 etcdserver: request timed outcontroller.go:178] failed to update node lease, error: etcdserver: request timed out request timed out Case @ 3 container runtime status check may not have completed yet.
原因: 容器把docker搞崩了,然后节点就异常了! 处理方案: for p in $(docker ps -q); do echo inspecting $p; docker inspect $p; echo complete; done; ps -ef | grep 最后的id kill 掉该进程 Case @4 invalid capacity 0 on image filesystem Warning InvalidDiskCapacity 101s kubelet invalid capacity 0 on image filesystem解决方案:systemctl restart containerd Case @5 时间不一致
/var/log/messages systemd : time has been changed
解决方案:重启kubelet kubelet 上报节点状态 源码分析:https://zhuanlan.zhihu.com/p/623840699
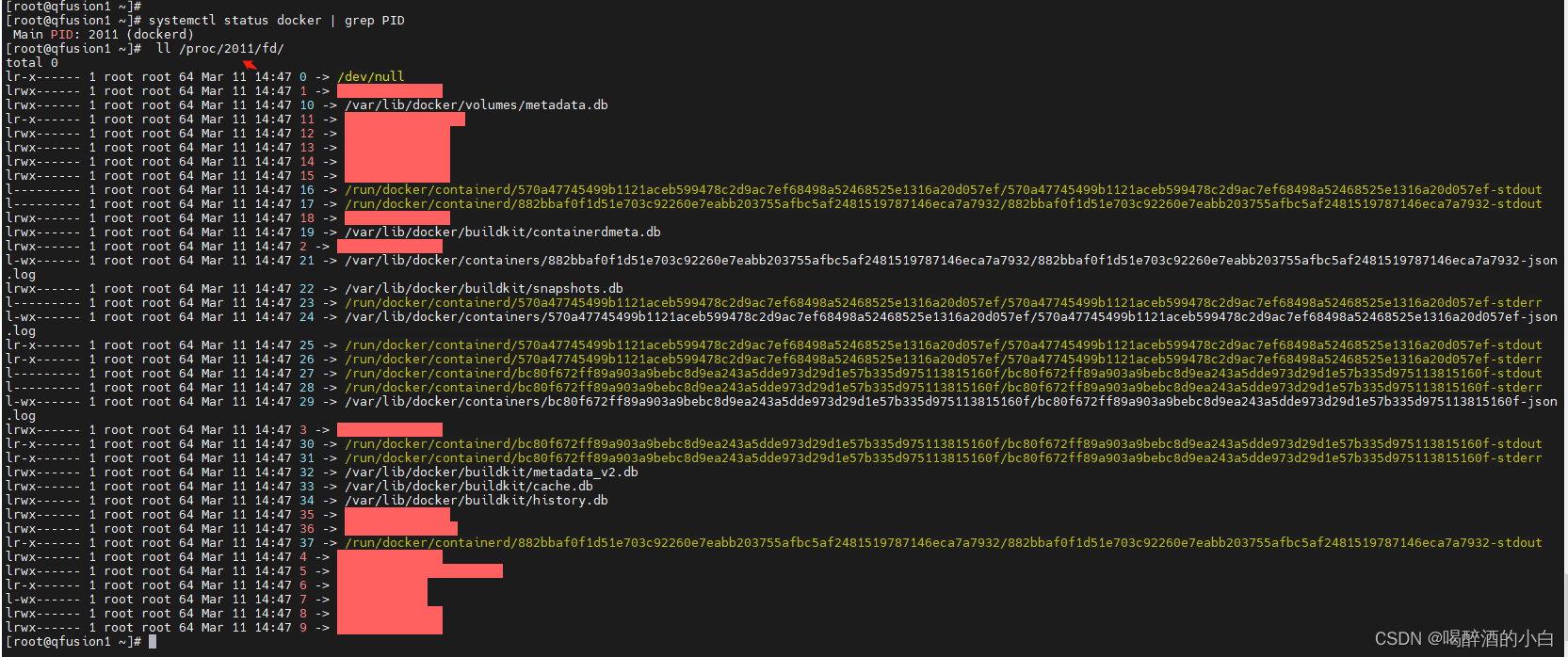
https://blog.csdn.net/whatday/article/details/125481727 ls > /tmp/proc.log cat /tmp/proc.log | wc -l ll /proc/pid/fd/ 能看一些,详细的可以使用lsof 命令 E0522 00:38:34.444337 1421 controller.go:187] failed to update lease, error: Put “https://k8smaster.qfusion.irds:60443/apis/coordination.k8s.io/v1/namespaces/kube-node-lease/leases/?timeout=10s”: net/http: request canceled (Client.Timeout exceeded while awaiting headers) 查看组件状态 ks get pod | grep etcd ks get pod | grep apiserver 收集组件日志 ks logs --since “72h” etcd-qfusion01 ks logs --since “72h” kube-apiserver-qfusion01 Leases Node heartbeats Case@9 System OOM encountered, victim process: prometheus原因:内存耗尽 排查:free -h 解决方案1:释放内存(或者重启宿主机) # 释放pagecache echo 1 > /proc/sys/vm/drop_caches # 释放dentries和inodes echo 2 > /proc/sys/vm/drop_caches # 释放pagecache、dentries和inodes echo 3 > /proc/sys/vm/drop_caches扩展:驱逐 驱逐信号 描述 memory.available memory.available := node.status.capacity[memory] - node.stats.memory.workingSet memory.available 的值来自 cgroupfs,而不是像 free -m 这样的工具。 这很重要,因为 free -m 在容器中不起作用,如果用户使用 节点可分配资源 这一功能特性,资源不足的判定是基于 cgroup 层次结构中的用户 Pod 所处的局部及 cgroup 根节点作出的。 这个脚本或者 cgroupv2 脚本 重现了 kubelet 为计算 memory.available 而执行的相同步骤。 kubelet 在其计算中排除了 inactive_file(非活动 LRU 列表上基于文件来虚拟的内存的字节数), 因为它假定在压力下内存是可回收的。 例如,如果一个节点的总内存为 10GiB 并且你希望在可用内存低于 1GiB 时触发驱逐, 则可以将驱逐条件定义为 memory.available |

 https://github.com/kubernetes/kubernetes/issues/101056
https://github.com/kubernetes/kubernetes/issues/101056 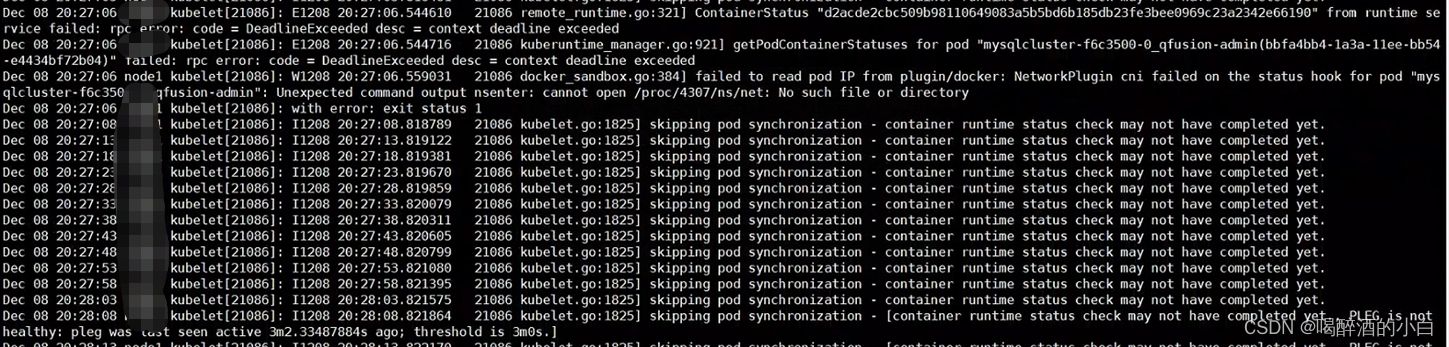
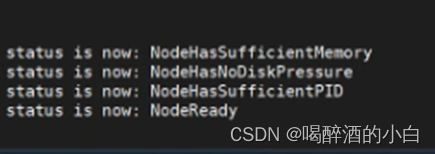
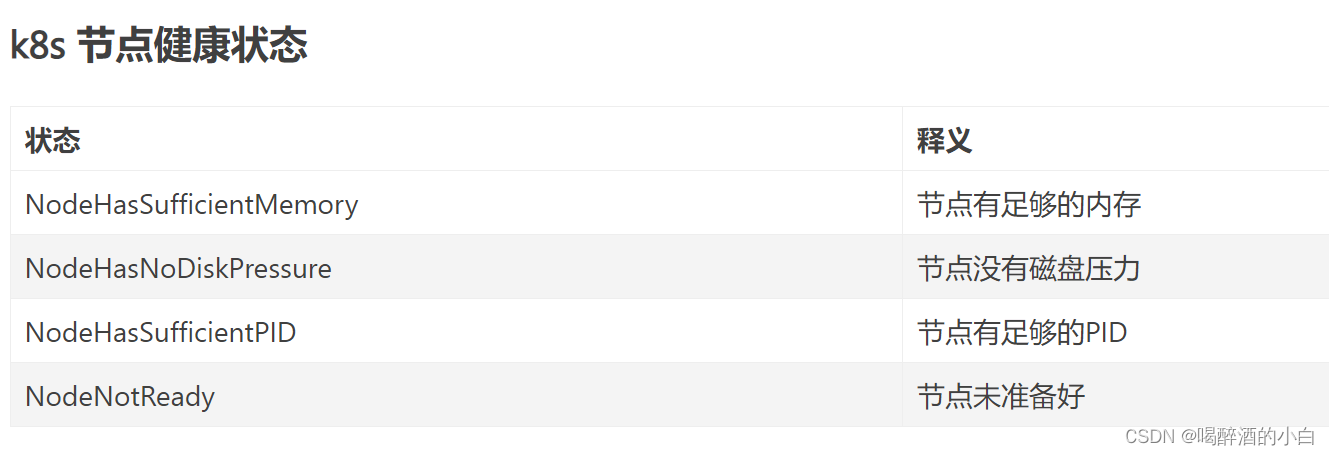 原因:该节点时间和其他节点时间不一致导致。
原因:该节点时间和其他节点时间不一致导致。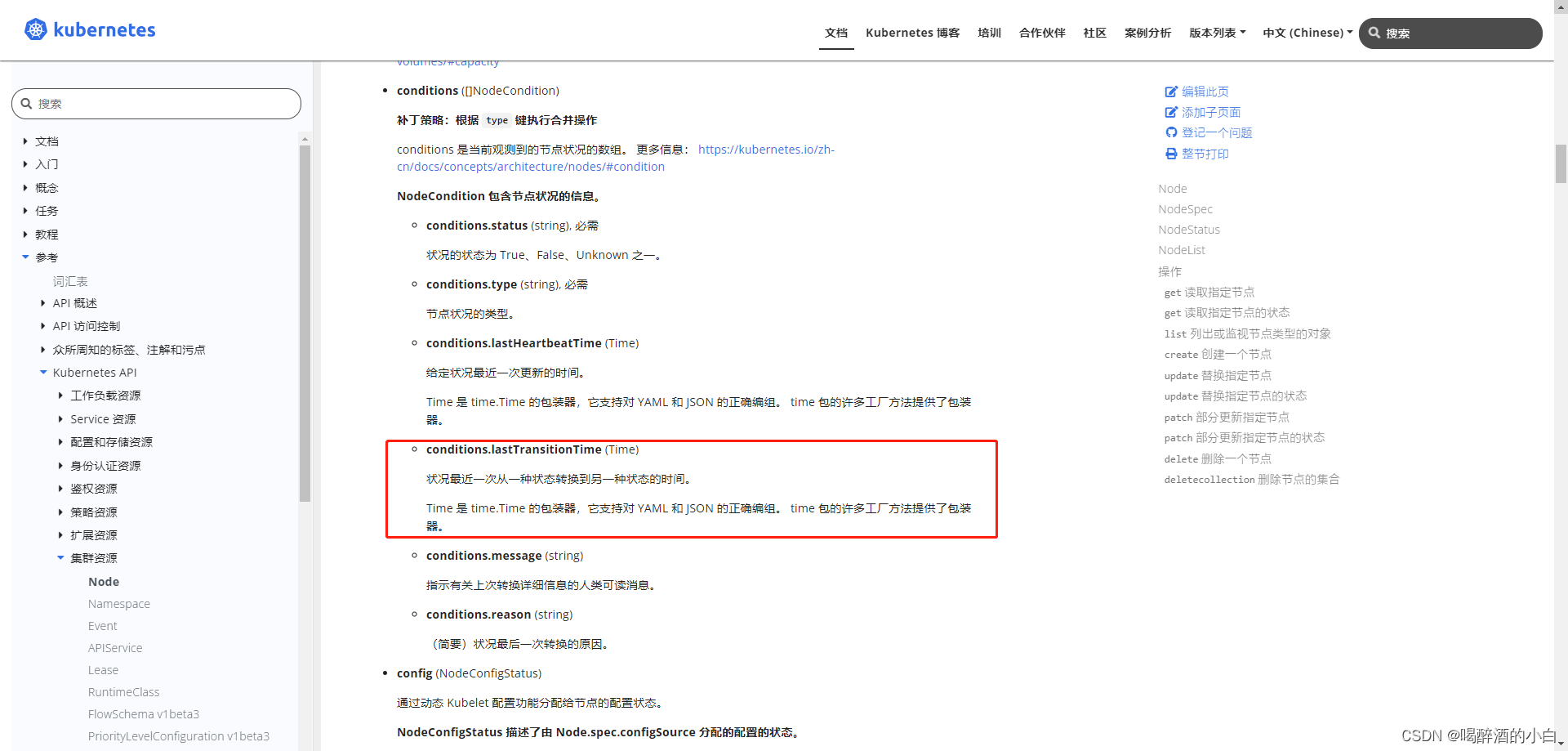

【本文地址】
今日新闻 |
推荐新闻 |